Google Cloud Summit 2019 大阪 に行ってきました
そこで、Professional Cloud Architect 認定試験ガイドの、Qwiklabs講座の無料チケットを頂いたので、そこでの覚え書きです
GCP リージョンとゾーン
| key |
value |
| Multi-Region |
Cloud Storageなど、一部のサービスのみ対応。冗長性をもたせ、リージョン同士を横断して分散されるようにするために、Googleが管理している。レイテンシは落ちる可能性があるため、プロダクト毎に事前に確認しておく必要がある |
| Region |
Zoneの集まり。どのロケーションに位置しているか。リージョン内のZoneは高速ネットワークで接続される(リージョン内でのネットワーク往復遅延時間は5ミリ秒未満 |
| Zone |
GCPリソースのデプロイエリアの事。リージョン内の耐障害ドメインのような物。データセンターではない(ゾーンが建物に対応しているというワケではない) |
IAM
| 役割 |
適用される範囲 |
| プリミティブ |
全サービスに適用。(オーナー,編集者,閲覧者,課金管理者) |
| 事前定義 |
特定のGCPサービス毎に適用。(プロジェクト,フォルダ,リソースなど) |
Cloud VPC
Deployment Manager
1
2
3
4
5
6
7
8
| // デプロイ(create)
$ gcloud deployment-manager deployments create [deploy名] --config [configファイル名.yaml]
// デプロイ(delete) → デプロイしたものが削除される
$ gcloud deployment-manager deployments delete [deploy名];
// 起動スクリプトの出力を確認
$ sudo journalctl -u google-startup-scripts.service
|
KubernetesクラスタでDockerイメージを使って公開するまで
Dockerイメージのビルド
ローカルでdockerビルドする。この時、イメージ名は、gcr.io/${PROJECT_ID}/[IMAGE]:[TAG]とする
1
| $ docker build -t gcr.io/${PROJECT_ID}/hello-app:v1 .
|
Container Registryにpushする
1
| $ gcloud docker -- push gcr.io/${PROJECT_ID}/hello-app:v1
|
Kubernetes クラスタを作成
1
2
3
4
5
6
7
| $ gcloud container clusters create hello-cluster --num-nodes=3
$ gcloud compute instances list
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS
gke-hello-cluster-default-pool-07a63240-822n us-central1-b n1-standard-1 10.128.0.7 35.192.16.148 RUNNING
gke-hello-cluster-default-pool-07a63240-kbtq us-central1-b n1-standard-1 10.128.0.4 35.193.136.140 RUNNING
gke-hello-cluster-default-pool-07a63240-shm4 us-central1-b n1-standard-1 10.128.0.5 35.193.133.73 RUNNING
|
クラスタにデプロイする
pushしたDockerイメージのコンテナをKubernetesクラスタにデプロイ
1
2
| // ポート8080でListenするhello-app
$ kubectl run hello-web --image=gcr.io/${PROJECT_ID}/hello-app:v1 --port 8080
|
runコマンドを実行すると、クラスタにDeploymentが作成される。(ここでは、 hello-webという名前のDeploymentが作成される)
1
2
3
4
| // Deploymentによって作成されたPodの一覧
kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-web-4017757401-px7tx 1/1 Running 0 3s
|
ポートを公開する
デフォルトでは外部IPは割り振られない。 kubectl exposeする
1
| $ kubectl expose deployment hello-web --type=LoadBalancer --port 80 --target-port 8080
|
スケーリングする
1
2
3
4
5
6
7
8
9
| // 3つにスケール
$ kubectl scale deployment hello-web --replicas=3
// 確認
kubectl get pods
NAME READY STATUS RESTARTS AGE
hello-web-4017757401-ntgdb 1/1 Running 0 9s
hello-web-4017757401-pc4j9 1/1 Running 0 9s
hello-web-4017757401-px7tx 1/1 Running 0 1m
|
Google Cloud のサービス
これ何?って思ったやつしか書いてません。(DB関係が特にややこしい)
| サービス |
is 何 |
| Cloud Pub/Sub |
キューイングシステムのようなもの |
| Cloud Endpoints |
AWSでいうAPI Gateway。Apigee Edgeっていう選択肢もある |
| Cloud Dataproc |
Hadoop, Spark, Hive, PigをGCE上に構築 |
| Cloud Bigtable |
列指向型NoSQL。トランザクションなし。大量のデータを低レイテンシで保存するのに適している。運用や分析を行うアプリに最適。永続的なハッシュテーブルと考える人もいる。HBaseとBigtableで同じAPIを使用しているため移植が可能 |
| Cloud Datastore |
Key-Value型NoSQL。トランザクションあり |
| Cloud Spanner |
分散型のリレーショナルデータベース。トランザクションあり |
ストレージオプションの比較

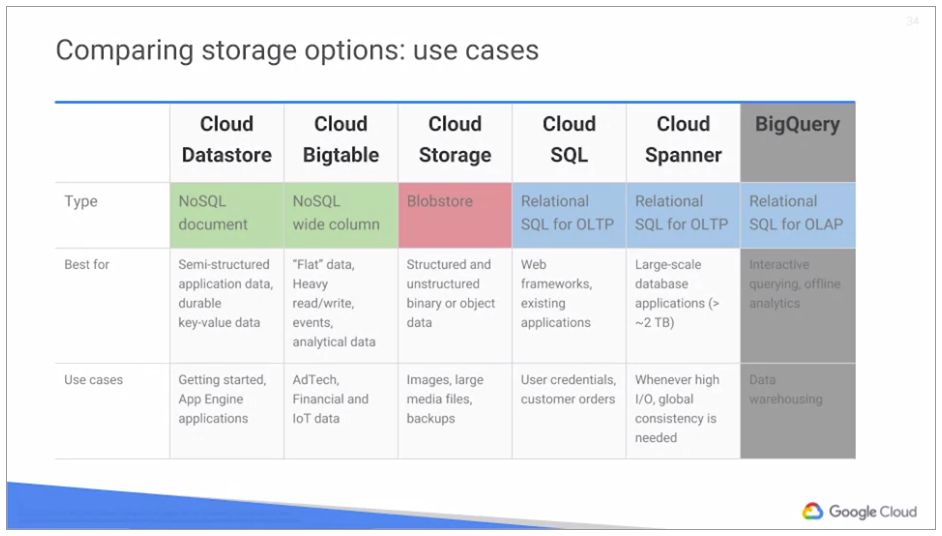
| key |
value |
| OLTP |
オンライントランザクション処理のこと。(Cloud Spanner または Cloud SQL) |
| BigQuery |
同時実行クエリには上限がある(100個) |
| Cloud Storage |
ストレージサービスの中では一番安価 |
| Cloud Storage |
Multi-regionalとRegionalがあり、RegionalはMulti-regionalより安価で冗長性は低い |
| Cloud Storage |
NearlineとColdlineがあり、Nearlineは月1回、Coldlineは年1回のアクセスに向いている |
| Cloud Storage |
NearlineとColdlineは、月あたりの保存データに対する料金は 安い。1GB単位の転送データに対する料金は 高い |
App engine
App Engine と Kubernetes Engine の違い


| key |
value |
| App Engine (standard) |
アプリのデプロイとスケーリングをサービスに任せたい人に適している |
| App Engine (flexible) |
App Engine(standard)とKubernetes Engineのいいとこ取り。ハイブリッドクラウド。GCE上のDockerコンテナで実行され、GAEがGCEのマシンを管理する |
| Kubernetes Engine |
Kubernetesの柔軟性をフル活用したい人向け |
ビッグデータと機械学習
Google Cloudのビッグデータソリューション
| service |
|
| Cloud Dataproc |
ビッグデータ用のオープンソースフレームワーク(Hadoop)。Hadoop, Spark, Hive, PigをGCE上に構築 |
| Cloud Dataflow |
ストリームとバッチを変換して拡充する、フルマネージドサービス。BigqueryからCloudStorageへ変換して同期したり |
| BigQuery |
データウェアハウス。ビッグデータのマイニング |
| Cloud Pub/Sub |
メッセージングサービス。イベントをリアルタイムで見たりするのに役立つ。1秒に100万件以上のメッセージ送受信が可能 |
| Cloud Datalab |
GCP上でデータ分析や可視化、機械学習のための分析環境。データ分析に人気のJupyterをベースに開発されている |
| MLib |
Apache Sparkの機械学習ライブラリ |
| TensorFlow |
ニューラルネットワークなどの機械学習アプリに適している |
| Cloud ML Engine |
デベロッパーやデータ サイエンティストが優れた機械学習モデルを構築し、本番環境で実行できるようにするマネージド サービス |
- Cloud Dataprocで、プリエンタブルなGCEインスタンスをバッチ処理に利用すると、インスタンスのコストが大幅に下がる
- Cloud Dataprocクラスタにデータが配置されると、SparkとSpark SQLを使ってデータマイニングができる。MLib(=Apache Sparkの機械学習ライブラリ)も利用できる
- BigQueryは、Cloud StorageやCloud Datastoreからデータを読み込んだり、1秒あたり最大10万行でBigQueryにストリーミングできる。
- BigQueryへのデータの読み書きは、SQLクエリだけでなく、Cloud Dataflow, Hadoop, Sparkも利用できる
- BigQueryは、ストレージとコンピューティングの料金は別。クエリを実行した分だけ料金が発生する。BigQueryストレージにデータが保存されてから90日が経過すると、ストレージ価格は自動的に割引される
- Cloud Datalabは、GCE上で動かす事を前提として、DockerイメージがGithubに公開されている
- Cloud MLでは、処理するデータが構造化データか非構造化データによって、一般的に2つのカテゴリに分かれている
機械学習API
| api |
|
| Vision API |
画像の内容を理解するためのAPI。数千のカテゴリに画像を分類 |
| Speech API |
音声をテキストに変換 |
| Natural Language API |
自然言語を理解するためのAPI。テキストを解析して、人、組織、場所、イベント、製品、メディアが言及されたらフラグを立てる |
| Translation API |
翻訳 |
| Video Intelligence API |
動画を分析し、アノテーションをつけたり、動画の中の名詞エンティティを識別し、出現するタイミングを識別したりできる。これにより、動画の内容を検索し、発見できるようになる |